



Monday
Jun052017
Using neural networks to create new music

I think creative sampling as we know it is going to change. Here is a sample I generated based on two Radiohead albums using a neural network. It is based on a Tensorflow implementation of the WaveNet algorithm described by Deepmind.
Deepmind is a Google-owned company focusing on artificial intelligence. They’re trying to create neural networks that are “intelligent”: can play video games, collaborate with clinicians, or solve how to use vastly less energy in data centers, for example. Last year, they published a paper about WaveNet, a deep neural network for speech and audio synthesis. While most neural network-related experiments in the field of sound and music are about the descriptors of sound or just data-sets describing audio (MIDI, for example), WaveNet actually looks at the tiniest grains of digital sound possible: samples.
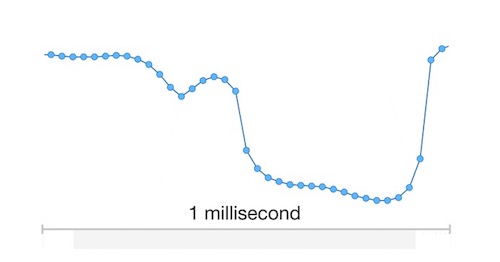
screenshot from a gif in the paper “WaveNet: A Generative Model for Raw Audio”
As you probably know, digital audio consists of measurements. A CD contains 44100 data points per second, that makes up the waveform which is, when played back, converted back into a continuous signal by the DAC (Digital to Analog-converter), which will then be converted back into sound by your speakers that make the air vibrate. The WaveNet model actually uses these samples as input, trying to learn what will come after the current sample. It creates a possibility space of where one can . If it has learnt this, it can then start generating samples, based on the model the neural network has created (As I’m just starting out in the field of neural nets, this might be totally wrong, please feel free to correct me!).
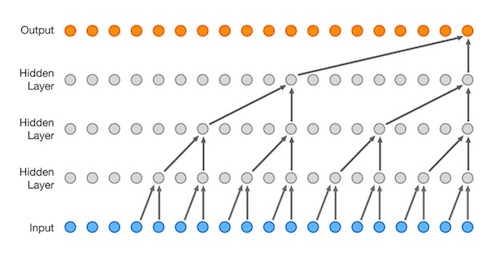
screenshot from a gif in the paper “WaveNet: A Generative Model for Raw Audio”
The paper on WaveNet describes how it was originally created to do better Text-to-Speech. The researchers found, however, that when they didn’t tell the model what to say, it still generated sound. But without meaning. The samples in the paper were super interesting to me. Half a year later, the all-round musician Espen Sommer Eide wrote a (great!) article on “Deep Learning Dead Languages”. Some audio from Espen’s article:
Audio examples from Espen Sommer Eide’s article
Moving to a new studio, and finally having the time to set up computers with a proper video card to work these algorithms, I wondered how a quite diverse database of musical material would work as a training set, and decided to train a neural net on two Radiohead albums for about a few days last week. What do you think of the results? While I don’t think it’s particularily musical, it has a very organic quality that could be very useful for sampling. To make this into a musical piece, we might need yet another algorithm to structure the creations from this WaveNet algorithm in (macro)time.
Since the Deepmind paper became public, various people have made several implementations available on Github. This is the one that I used.
 Post a Comment
Post a Comment



